Training an Unbeatable Tic-Tac-Toe AI using Reinforcement Learning
Building the Environment
Defining the Problem
Before we can begin training our agent, we first need to define the problem. You are probably thinking: But we already know the problem, its tic-tac-toe! That is true, however, we need to define the problem in a way that the agent can understand and interact with. To do this, we need to answer some questions:
- How many agents play the game? Do we have two agents that play against one another, or one agent that plays against a non-ml algorithm?
- How do agents "see" the board? How do we represent the tic-tac-toe board so that a neural network can understand it?
- What actions can an agent take? How do these actions relate to the game?
- When can an agent take those actions? Are some actions only valid under certain circumstances?
The answers to these questions are interconnected, and depend on our training strategy. After many hours of experimentation, I settled on an approach that achieves acceptable results with relatively little training. To significantly shorten this blog post, I will only be sharing the final approach that I used. Don't let that stop you from trying something else!
Single vs. Multi Agent
First, we need to decide on how many agents we will use. If we use a single-agent environment, the other player must be represented by an algorithm. Should that algorithm be random, or follow a pre-defined strategy that we hard-code?
- If our agent plays against a non-random algorithm, we could run the risk of it learning niche strategies that fall apart when playing against a new opponent. This would occur if the algorithm we design has flaws. In a simple game of tic-tac-toe, it is easy to design a perfect algorithm, but we might not have access to one in more complicated projects.
- If our agent plays against a random algorithm, it might take a long time to learn the best strategy. This is because the opponent is random, and will not always exploit a mistake made by the agent. The only way for our agent to learn from its mistakes is to receive negative reward (losing), which means the opponent must exploit those mistakes.
Additionally, we need to think about which player(s) our agent will represent. Do we want our agent to be able to play as X and O? If we train our agent to play both roles, are there any strategies that are different based on which role our agent assumes? Does our agent need to be aware of which player it is acting as?
I decided that I wanted two agents, one for X and the other for O. I could train these agents separately against an algorithm, but I would run into the dilemma outlined above. Instead, I decided to train them against one another. The idea is that the agents start off completely random, then slowly improve their strategies. Since they are playing against each other, when one agent improves its strategy the other agent will be challenged to improve as well. This way, each agent has a flawless opponent without us hard-coding a strategy.
It is worth mentioning that this approach can introduce a complication. By having multiple agents learn simultaneously, we create a non-stationary environment. From either agent's perspective, the behavior of the opponent changes throughout the training lifetime. This is in stark comparison to single agent training, when the opponent keeps the same strategy forever. In this project, I found that training converged despite having a non-stationary environment, but this is not always the case.
Observations and Actions
While we can look at a tic-tac-toe board and inherently understand what
is happening, our agent needs a more explicit representation.
We will represent the board as a 3x3 numpy array.
Each location in the array starts as 0, then changes to 1 or -1
depending on which player claims it during play.
Unless we use specific tools (CNN), neural networks expect a one-dimensional
input tensor.
To produce this, we will flatten the numpy array from shape (3,3) to (9,).
Each turn, one agent claims a square while the other agent does nothing. We will represent each square as an action, so if player X wants to claim the bottom left square, it would take action 6:

That's great, but what happens if square 6 is already claimed? The agent needs to understand that depending on the observations it receives, some actions are invalid. To achieve this we could return a negative reward and terminate the game whenever and agent makes an invalid move. However, this greatly hinders training progress for a few reasons:
- Not only must our agents learn how to win the game, they must also learn the rules. This increases the complexity of our goal and ultimately the neural networks we will use.
- Until our agents learn the rules, most games will terminate early due to invalid actions. While the offending agent will be penalized, the opponent will not learn anything from this training sample. We lose data efficiency, since only one agent learns something from each game.
Alternatively, we can provide an action mask, which tells the agent which actions are valid. The action mask is a binary array, with 1's corresponding to valid actions and 0's corresponding to invalid actions. In this example game, X is about to move:
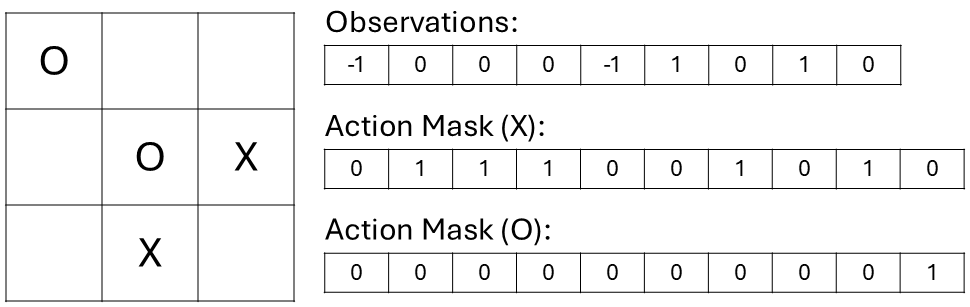
You might notice that our masks have an extra element! Indeed, the masks have 10 elements, while our observation vector has only 9. Look closely, and you may also notice that the action mask for player O is all zeros — except for this extra element. That's because we are actually going to use 10 actions in our environment. Due to some compatability issues with RlLib's new API, we need to use a parallel environment, rather than a turn-based one. In a parallel environment, agents are expected to take an action at every time step. There is no concept of "turns". Consequently, player O will pick an action even if it is player X's turn.
We could just ignore this action and update the environment based on X's action. But the player O expects the environment to change based on the action it picks. It will assume that any changes in the environment are a product of its actions. See the issue? Player O will think that its action caused the board to change and will update its neural network accordingly. This is a faulty update since that action had nothing to do with the observed change.
The solution is to have a "do nothing" action. When it's not a player's turn, the only "action" it is allowed to take is "do nothing". This is why the action mask has 10 elements in it. Since it is not player O's turn, the action mask is zeroed-out except for the last element.
Petting Zoo
Okay, enough talk. How do we actually code the environment? We will use a popular library called PettingZoo to create our multi-agent environment. PettingZoo takes inspiration from Gymnasium, the go-to Python libraries for single-agent RL environments.
Our environment will be a python class, which we will later provide to our training code. Let's begin by defining the initialization logic:
1 import gymnasium as gym2 import numpy as np3 from gymnasium import spaces4 from gymnasium.core import ObsType, ActType5 from pettingzoo import ParallelEnv6 from pettingzoo.utils.env import AgentID, ActionType78 class MultiAgentTicTacTie(ParallelEnv):9 metadata = {'render.modes': ['human'], "name": "TicTacToe"}1011 def __init__(self, options: dict, render_mode=None):12 self.render_mode = render_mode13 self.possible_agents = ['X', 'O']14 self.__tie_penalty = options.get('tie_penalty', 0.25)15 self.__random_first = options.get('random_first', False)1617 @functools.lru_cache(maxsize=None)18 def observation_space(self, agent) -> gym.spaces:19 return spaces.Dict({20 'observations': spaces.Box(low=-1, high=1, shape=(9,), dtype=int),21 'action_mask': spaces.Box(low=0.0, high=1.0, shape=(10,), dtype=int)22 })2324 @functools.lru_cache(maxsize=None)25 def action_space(self, agent) -> gym.spaces:26 return spaces.Discrete(10)
Our environment inherits from PettingZoo's ParallelEnv class, which means
that each agent takes an action at every time step.
For our purposes, metadata doesn't affect our project.
These are just values that PettingZoo expects every environment to have.
In the initializer, we declare the types of agents that can participate
in the environment with: self.possible_agents = ['X', 'O'].
We also retrieve some configuration values from the options dictionary.
These values serve as hyperparameters during training, so we will discuss
them in the next section.
The observation_space and action_space methods delineate how agents
should interact with our environment.
Each turn, agents should submit a number (0-9) to the environment.
This is represented by spaces.Discrete(10).
After the turn is processed, agents will receive a dictionary containing
the observations and action mask we discussed above.
These are arrays, so they are represented by spaces.Box().
Read more about Gymnasium spaces
here.
Reset Method
Next, we need to define what happens at the beginning of each game. Under the hood, Ray will use a single instance of our environment class to simulate thousands of tic-tac-toe games. We need to provide a "reset button" that is called at the beginning of a new game:
1 def reset(2 self,3 seed: int | None = None,4 options: dict | None = None,5 ) -> tuple[dict[AgentID, ObsType], dict[AgentID, dict]]:6 self.agents = self.possible_agents[:]7 self.num_moves = 08 self.__game = Game()9 if self.__random_first:10 self.__turn = 'O'11 idx = np.random.choice(np.arange(9))12 self.__game.move(*np.unravel_index(idx, (3, 3)))13 else:14 self.__turn = 'X'15 observations = {16 agent: {17 'observations': self.__game.board.flatten(),18 'action_mask': self.__create_mask(agent == self.__turn)19 } for agent in self.agents20 }21 infos = {agent: {} for agent in self.agents}22 return observations, infos
- The most important part is that we instantiate a new
Gameobject. This is a custom class I created to track the logic of tic-tac-toe. The code for it is provided at the end of this section. - If the
random_firsthyperparameter istrue, we make a random move then indicate that player O is up next. If it isfalse, we simply indicate that player X is up next. - We create the
observationsandinfosdictionary, which are returned to the caller. The observations are contained in theboardproperty of ourGameobject, which we flatten. The__create_maskmethod automatically creates an appropriate action mask.
Step Method
Now we need to define what happens on every environment step.
In the step method we:
- Receive the agent actions as a dictionary.
- Use the current player's action to update the environment
by calling
self.__game.move - Create new observations based on the updated board
- If the game is over, signal that all agents are terminated from the environment.
Based on the outcome, set the reward of each agent.
Notice this is where the
tie_penaltyhyperparameter is used. - Switch turns, then return the five required dictionaries.
1 def step(2 self, actions: dict[AgentID, ActionType]3 ) -> tuple[4 dict[AgentID, ObsType],5 dict[AgentID, float],6 dict[AgentID, bool],7 dict[AgentID, bool],8 dict[AgentID, dict],9 ]:10 rewards = {agent: 0.0 for agent in self.agents}11 if actions[self.__not_turn()] != 9:12 rewards[self.__not_turn()] = -0.11314 action = actions[self.__turn]15 if action is not None:16 self.__game.move(*np.unravel_index(action, (3, 3), order='C'))17 self.num_moves += 11819 # Update Observations20 observations = {21 agent: {22 'observations': self.__game.board.flatten(),23 'action_mask': self.__create_mask(agent != self.__turn)24 } for agent in self.agents25 }26 terminations = {agent: False for agent in self.agents}27 truncations = {agent: False for agent in self.agents}28 infos = {agent: {} for agent in self.agents}2930 # Check Reward conditions31 if self.__game.game_over:32 terminations['X'] = True33 terminations['O'] = True34 terminations['__all__'] = True35 if self.__game.winner_symbol == 'X':36 rewards['X'] = 137 rewards['O'] = -138 infos['X']['outcome'] = 'win'39 infos['O']['outcome'] = 'lose'40 elif self.__game.winner_symbol == 'O':41 rewards['X'] = -142 rewards['O'] = 143 infos['X']['outcome'] = 'lose'44 infos['O']['outcome'] = 'win'45 else:46 rewards['X'] = self.__tie_penalty47 rewards['O'] = self.__tie_penalty48 infos['X']['outcome'] = 'tie'49 infos['O']['outcome'] = 'tie'5051 self.__switch_turn()52 return observations, rewards, terminations, truncations, infos
If you are unfamiliar with PettingZoo or find this to be somewhat overwhelming, consider reading their documentation for a gentle introduction. This article is not designed to be a thorough explanation of every concept. The API on parallel envs is also a good resource.
Helper Methods
Lastly, we need to define a few helper methods referenced in the above snippets.
The main one of concern is __create_mask, which creates the action mask.
The argument to_move_next indicates if we are creating a mask for the agent
that moves or the agent who will "do nothing" next turn.
- First, we create a mask from the game board called
m1. This mask is 1 for empty squares and 0 for occupied squares. Note, this uses the concept of boolean indexing. - If the agent is moving next turn, we copy over
m1to the first 9 elements of our mask. We set the last element to 0, since the agent making a move should not be allowed to "do nothing". - If the agent is not moving next turn, we set everything to 0 except the last element. Indicating that the agent is only allowed to "do-nothing".
1 def __create_mask(self, to_move_next: bool) -> np.ndarray:2 mask = np.ones((10,), dtype=np.int8)3 m1 = np.ones((3, 3), dtype=np.int8)4 occupied = self.__game.board != 05 m1[occupied] = 06 if to_move_next:7 mask[9] = 08 mask[0:9] = m1.flatten()9 else:10 mask[0:9] = 011 return mask1213 def __switch_turn(self) -> None:14 self.__turn = 'X' if self.__turn == 'O' else 'O'1516 def __not_turn(self) -> Literal['X', 'O']:17 return 'X' if self.__turn == 'O' else 'O'
Game Logic
Our PettingZoo environment uses a separate object to keep track of the tic-tac-toe game. We need to code this class ourselves. My implementation is relatively intuitive if you are a regular Python user.
- A new game is started with the initialization function, where we create an empty board, set the current player to X, and indicate that no one has won yet.
- The environment calls the move function until the game is over. A and B represent the row and column indices of the player's action.
- We communicate the status of the game via the five properties defined at the top.
- The
__check_winnermethod determines if the game is over.
1 class Game:23 @property4 def remaining_moves(self):5 return np.sum(self.board == 0)67 @property8 def board(self) -> np.ndarray:9 return self.__board1011 @property12 def turn(self) -> Literal['X', 'O']:13 return 'X' if self.__player == 1 else 'O'1415 @property16 def game_over(self) -> bool:17 return self.__winner != 0 or self.remaining_moves == 01819 @property20 def winner_symbol(self) -> Literal['X', 'O'] | None:21 if self.__winner == 1:22 return 'X'23 elif self.__winner == -1:24 return 'O'25 else:26 return None2728 def __init__(self):29 self.__board = np.zeros((3, 3), dtype=np.int8)30 self.__player = 131 self.__winner = 03233 def __switch_player(self) -> None:34 self.__player *= -13536 def move(self, a: int, b: int) -> None:37 if self.game_over:38 raise ValueError('Game is already over!')39 if self.__board[a, b] != 0:40 raise ValueError('Space is occupied')4142 self.__board[a, b] = self.__player43 if self.__check_winner(self.__board, self.__player):44 self.__winner = self.__player45 else:46 self.__switch_player()4748 # noinspection DuplicatedCode49 @staticmethod50 def __check_winner(board: np.ndarray, player: int) -> bool:51 truth: np.ndarray = np.equal(board, player)52 if any(np.sum(truth, axis=0) == 3):53 return True54 if any(np.sum(truth, axis=1) == 3):55 return True56 if all([truth[0, 0], truth[1, 1], truth[2, 2]]):57 return True58 if all([truth[0, 2], truth[1, 1], truth[2, 0]]):59 return True60 return False
Now we have all the code that defines how our agents play Tic-Tac-Toe and interact with the environment to receive reward. Next up, we will explore Ray's RlLib library to define the training logic and experiment with hyperparameters!